Tout propriétaire de site web, tout référencement expérimenté ou développeur passionné a connu ce moment de frustration : vous publiez un article d'une profondeur technique inouïe, ou vous lancez une nouvelle page produit méticuleusement optimisée. Vous rafraîchissez la Search Console, vérifiez les opérateurs de recherche Google (site:), et pourtant... le néant. Rien. L'invisibilité totale.
Pourquoi le moteur de recherche le plus puissant au monde, capable d'analyser des milliards de pages par jour, ne détecte-t-il pas votre contenu de manière automatique et immédiate ? Pourquoi existe-t-il ce délai, parfois imperceptible, parfois interminable, entre la mise en ligne et l'apparition dans les SERPs (Search Engine Results Pages) ?
Cet article a pour but de démystifier ce processus. Nous allons décortiquer les rouages complexes de l'infrastructure de Google, en nous basant sur les documentations officielles de Search Central, les observations récentes de la communauté SEO (2024) et l'analyse de logs serveur. Loin des idées reçues sur le "sandbox", nous allons explorer la réalité technique d'un système régi par des files d'attente, des coûts de calcul et des priorités algorithmiques strictes.
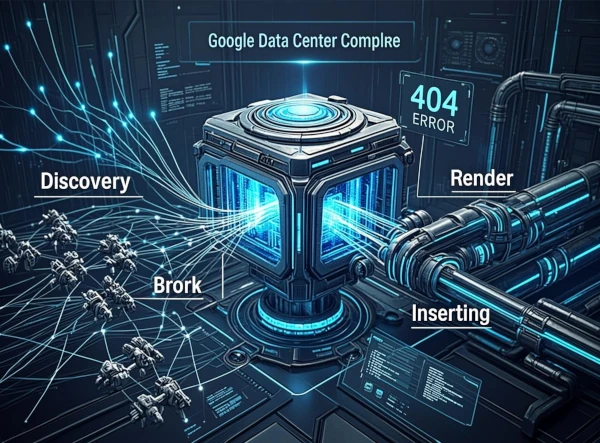
I. Le Cycle de Vie d'une Page chez Google : Découverte > Crawling > Rendering > Indexation
Comprendre le délai d'indexation requiert de saisir que l'Indexation n'est qu'une étape finale d'un pipeline long et complexe. Google ne "lit" pas votre page comme un humain ; il doit d'abord la trouver, la télécharger, la construire, puis la décider digne d'être stockée.
1. La Découverte (Discovery) : Le point de départ
Tout commence ici. Avant même de lire votre contenu, Google doit connaître l'existence de l'URL. Contrairement à une croyance populaire, Google ne "scanne" pas l'internet en temps réel comme un radar. Il suit des chemins.
La méthode principale reste le maillage interne. Le Crawling Googlebot parcourt les liens hypertextes qu'il trouve sur les pages qu'il connaît déjà. Si vous créez une nouvelle page sans aucun lien pointant vers elle (orphan page), elle est techniquement invisible pour cette méthode primaire. C'est là que le fichier sitemap.xml intervient comme un filet de sécurité, suggérant explicitement des URLs à l'explorateur.
2. L'Exploration (Crawling) : La consommation de ressources
Une fois l'URL découverte, Googlebot tente une requête HTTP vers votre serveur. Cette phase consomme de la bande passante et des ressources serveur. Google ne peut pas explorer l'intégralité du web à chaque seconde ; il doit allouer ses ressources intelligemment. C'est ici que la notion de Budget de crawl devient critique.
Lorsque Googlebot télécharge le HTML brut de votre page, il obtient le code source. Cependant, ce code source n'est souvent pas ce que l'utilisateur final voit, surtout dans une architecture web moderne.
3. Le Rendu (Rendering) : Le goulot d'étranglement JavaScript
C'est l'étape la plus coûteuse en calcul. Pour comprendre la page comme un utilisateur (contenu dynamique, liens générés par JS, balisage structuré), Google doit exécuter le JavaScript.
Le Rendering JavaScript ne se fait pas instantanément pour chaque URL. Google différencie le "Crawling" (récupération rapide du HTML) du "Rendering" (exécution du code). Si votre site repose massivement sur le Client-Side Rendering (CSR), Google peut indexer une page vide ou incomplète si le rendering est différé. En 2024, Googlebot utilise une version d'époque de Chrome (Evergreen Googlebot), mais il a toujours des limites de taille de WAF (Web Assembly Framework) et de temps d'exécution.
4. L'Indexation : La décision finale
Même après crawl et rendu réussis, la page n'est pas garantie d'être indexée. Google passe au crible plusieurs filtres :
- La qualité du contenu : Est-il unique et apporte-t-il de la valeur ?
- Le contenu dupliqué : Est-ce une copie d'une autre page (canonisation) ?
- Les directives meta : La balise
noindexest-elle présente ?
Si la page passe ces filtres, elle est ajoutée à l'index inversé de Google. Le délai entre l'étape 1 et 4 est ce que nous appelons l'indexation différée.
II. Le "Crawl Budget" : La gestion de la pénurie de ressources
Le concept de Crawl Budget est souvent mal compris. Pour beaucoup de sites, ce n'est pas une préoccupation. Si vous avez moins de quelques milliers d'URLs, Google vous explorera probablement assez souvent. Cependant, pour les sites e-commerce massifs ou les sites web d'actualité, comprendre le budget de crawl est vital pour l'indexation rapide.
Qu'est-ce qui définit le Crawl Budget ?
Le budget est déterminé par deux facteurs principaux :
1. La Limite de Débit (Crawl Rate Limit) :
C'est le nombre maximum de connexions simultanées que Googlebot peut établir avec votre serveur sans le saturer. Si votre serveur est lent (TTFB élevé) ou s'il renvoie beaucoup d'erreurs 5xx (Timeouts, Internal Server Error), Google réduit automatiquement cette limite pour protéger votre infrastructure.
2. La Demande d'Exploration (Crawl Demand) :
C'est l'appétit de Google pour votre contenu. Il dépend de : * La popularité de vos URLs (nombre de backlinks, trafic organique). * La fraîcheur requise (si votre site est un média d'actualité, la demande est plus élevée).
Screaming Frog Log File Analyzer ou ELK Stack révèle souvent que Googlebot ne visite que 30 à 60% d'un gros site chaque mois. Si vous publiez une nouvelle page sur un site à faible autorité (Domain Rating faible) avec un maillage interne pauvre, cette page peut attendre des semaines avant que la "demande" ne soit suffisante pour déclencher le crawl.Pour optimiser le budget, il faut éliminer le gaspillage : corriger les erreurs 404, rediriger les chaînes de redirections infinies, et éviter de soumettre des pages filtrées (paramètres d'URL inutiles) dans le sitemap. Chaque URL inutile explorée est une URL utile qui attend.
III. L'impact du JavaScript et du Rendu (Rendering) sur la vitesse d'indexation
En 2024, le web est majoritairement dynamique. Frameworks React, Vue.js, Angular... Ces technologies changent la donne pour l'indexation instantanée.
Le délai de la "Seconde Vague d'Indexation"
Pour les sites "Heavy JS", Google suit souvent ce processus en deux phases :
- Phase 1 (Rapide) : Crawl du HTML, indexation du contenu statique (meta, titre, contenu initial).
- Phase 2 (Lente) : File d'attente pour le rendering. Googlebot exécute le JS, voit le contenu généré asynchronement, et met à jour l'index.
Ce délai entre la phase 1 et 2 peut aller de quelques secondes à plusieurs jours. Si votre contenu critique (titres H1, descriptions produits) est injecté uniquement par JavaScript, votre page risque d'être indexée avec du contenu vide ou générique dans un premier temps. C'est un frein majeur à une indexation rapide.
Hydratation et Server-Side Rendering (SSR)
Pour contrer ce problème, les experts recommandent le SSR ou la Static Site Generation (SSG, ex: Next.js). En envoyant le HTML déjà "rendu" côté serveur, vous permettez à Google d'indexer tout le contenu lors de la phase 1, éliminant le temps d'attente du rendering.
IV. Le rôle crucial du Maillage Interne et des Backlinks
L'architecture de votre site dicte la Priorité d'exploration. Googlebot ne visite pas les pages au hasard ; il suit les signaux de popularité.
Profondeur de Crawl (Click Depth)
La règle d'or est simple : plus une page est proche de la page d'accueil (en nombre de clics), plus elle sera crawlée et indexée rapidement. Une page située à 4 ou 5 niveaux de profondeur (sans lien direct depuis le menu ou le footer) est souvent considérée comme moins importante par Google.
Si vous voulez une indexation instantanée pour une nouvelle page, le " coup de boost " le plus efficace est d'ajouter un lien temporaire vers cette page sur votre page d'accueil. Cela signale à Googlebot : "Ceci est important, venez voir maintenant".
Les Backlinks Externes comme Catalyseur
Un lien entrant (backlink) depuis un site à forte autorité et à fort trafic accélère non seulement le classement, mais aussi la découverte et le crawl. Le Googlebot re-crawle les sites populaires très fréquemment (parfois toutes les minutes). Si votre site est lié depuis une telle page, le robot "tombera" sur votre lien presque immédiatement et ajoutera votre URL à sa file d'attente de crawl haute priorité.
V. La File d'Attente de l'Indexation : Pourquoi le délai ?
Même après un crawl réussi, la page entre dans une file d'attente globale. Google doit traiter des milliards de pages par jour.
La File d'attente d'indexation est gérée par des algorithmes de priorisation. Les facteurs influençant la position dans la file d'attente incluent :
- La confiance du domaine : Un site historique sans pénalités est crawlé plus vite.
- Les mises à jour de contenu : Google détecte-t-il un changement significatif par rapport à la version précédente (via le last-modified header ou ETag) ?
- Les violations de directives : Si votre site a déjà eu des problèmes de spam ou de cloaking, l'indexation peut être ralentie manuellement ou automatiquement pour vérification.
En 2024, avec l'essor du contenu généré par IA, Google a renforcé ses systèmes de détection de contenu de faible qualité. Si une page semble être du "spam" ou du contenu sans valeur ajoutée (E-E-A-T faible), elle peut rester en attente indéfiniment, voire être ignorée, malgré un crawl correct.
VI. Outils et Accélération : Reprendre le contrôle
Face à cette attente passive, existe-t-il des solutions actives ? Oui, mais elles doivent être utilisées avec intelligence.
Google Search Console : La Soumission d'Index
L'outil "Inspection d'URL" permet de demander une Soumission d'index manuelle. Cela ne "force" pas l'indexation, mais déplace l'URL en haut de la file d'attente de crawl. C'est particulièrement utile pour les pages orphelines ou les corrections urgentes de contenu.
L'API Indexing
Pour les sites d'actualité ou les pages avec une durée de vie très courte (événements sportifs, offres flash), Google met à disposition l'API Indexing. Contrairement à la soumission manuelle via l'interface, l'API permet d'envoyer jusqu'à 200 requêtes par jour par URL.
Attention : L'API Indexing ne garantit pas l'indexation, elle garantit seulement un crawl rapide. Elle est réservée aux cas d'usage spécifiques (JobPosting, BroadcastEvent, etc.) ou aux structures fortement autorisées.
Top 5 des Erreurs Techniques Bloquant l'Indexation
- Erreur 5xx (Server Errors) : Si votre serveur plante lors du passage de Googlebot, il reviendra plus tard (règle du "backoff"). Répété, cela stoppe l'indexation.
- Robots.txt bloquant : Une règle
Disallow: /ouNoindexdans le fichier mal configuré peut empêcher l'accès au contenu critique. - Temps de chargement excessif (TTFB > 2s) : Googlebot a peu de patience. Une page lente est souvent abandonnée avant la fin du téléchargement.
- Contenu injecté par session ou Cookies : Si le robot ne gère pas les cookies et que tout votre contenu dépend d'une session active (ex: "Veuillez accepter les cookies"), la page reste vide pour Google.
- Balises Meta Noindex ou Canonicals pointant ailleurs : Une erreur de configuration CMS qui applique un
noindexpar défaut sur les nouvelles pages empêche toute indexation.
VII. Tableau Comparatif : Méthodes d'Indexation et Délais Observés
Ce tableau synthétise les délais moyens observés en 2024 selon la méthode de découverte et le type de site, basés sur des retours de la communauté SEO et des analyses de logs.
| Méthode de Découverte / Type de Site | Délai Moyen d'Indexation (Observé) | Fiabilité | Impact de la GSC / API |
|---|---|---|---|
| Maillage Interne (Site Autorité Élevée) | < 1 heure à 24h | Très Haute | Accélération mineure (déjà rapide) |
| Maillage Interne (Site Autorité Faible) | 1 semaine à 3 mois | Moyenne (Risque d'orphelinat) | Forte amélioration (Indispensable) |
| Sitemap XML | 24h à 1 semaine | Basse (Suggestion uniquement) | Aucun impact direct (déjà soumis) |
| Backlink "Juicy" (Lien de haute qualité) | < 24h | Haute (Découverte active) | N/A |
| SPA (React/Vue) sans SSR | 48h à 1 semaine (Rendering différé) | Moyenne (Risque contenu vide) | Indispensable pour forcer le Rendering |
| API Indexing (JobPosting/News) | Quelques minutes | Haute (si contenu valide) | Le mécanisme lui-même |
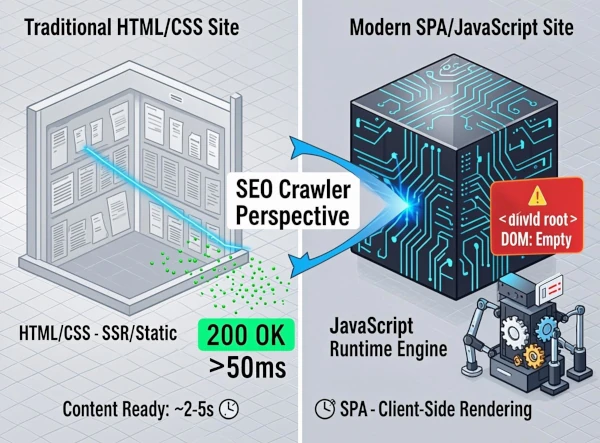
VIII. Étude de Cas : Statique vs SPA (Single Page Application)
Pour illustrer l'impact de l'architecture, observons deux scénarios réels.
Cas A : Le Blog Statique (HTML simple)
Un article est publié. Le HTML contient tout le contenu, le titre, les méta-données. Googlebot crawler l'URL, voit le code HTML, l'analyse. Le contenu est directement disponible pour l'indexation. Résultat : Indexation en 15 minutes via la GSC.
Cas B : La Web App (React Heavy)
Un nouvel outil interactif est publié. Le HTML initial contient seulement un <div id="root"></div>. Tout le contenu est chargé via un appel API et injecté par JS. 1. Googlebot Crawl : Récupère le HTML vide. (Statut : Découvert). 2. File d'attente Rendering : La page attend son tour pour être exécutée. 3. Rendering : Le JS s'exécute, remplit le DOM. (Statut : Crawlé). 4. Indexation : Le contenu est enfin lu. Résultat : Indexation en 4 à 5 jours sans intervention, car la phase de Rendering est en file d'attente prioritaire faible.
Cette étude démontre que l'architecture technique est le facteur numéro un de l'indexation différée aujourd'hui.
IX. L'influence des Mises à Jour d'Algorithme
Enfin, il est crucial de noter que les délais d'indexation fluctuent en fonction de l'activité de Google. Lors des mises à jour majeures du "Core Update", les ressources de crawling sont souvent réallouées pour la re-calcul du ranking et la re-évaluation des pages existantes. Les nouveaux contenus peuvent voir leur indexation ralentie temporairement pendant ces périodes de turbulence, le système priorisant la mise à jour de l'existant sur l'ingestion du nouveau.
Conclusion
L'indexation instantanée est un mythe, sauf pour les acteurs dominants disposant d'une infrastructure technique parfaite et d'une autorité incontestée. Pour la grande majorité des webmasters, l'indexation est une lutte contre les files d'attente et les coûts de calcul de Google.
En comprenant que l'indexation est le résultat final d'un pipeline complexe (Découverte, Crawling, Rendering, Indexation), vous pouvez agir techniquement pour réduire les frictions : 1. Optimisez votre Crawl Budget (nettoyage technique, vitesse serveur). 2. Simplifiez le Rendering (SSR, HTML statique pour le contenu critique). 3. Utilisez intelligemment le Maillage Interne pour la découverte. 4. Maîtrisez la Google Search Console et l'API Indexing pour les priorités.